Appendix
命令カバレッジとソースコードの実行行数
gcovの出力であるgcovファイルを参照すれば、ソースコードのどの行を何回実行したのか容易に確認することができます。しかし、関数のすべての行を実行したとしても、その関数の命令カバレッジが100%になっているとは限りません。
例として、glib-2.20.5のglib/guniprop.cにある関数real_toupper()†をとりあげてみます。FreeBSD 7.1で次のようにビルドして、付属のテストを実行してみます。
% tar jxf glib-2.20.5.tar.bz2
% cd glib-2.20.5
% ./configure CFLAGS="-O0 -fprofile-arcs -ftest-coverage" \
CPPFLAGS="-I/usr/local/include" LDFLAGS="-L/usr/local/lib -lintl" \
--with-libiconv=gnu --disable-shared --enable-static
% gmake
% gmake -C tests check
次にgcov、もしくはcovertureを使って、glib/guniprop.cのgcovファイルを出力します。そして、そのgcovファイルを眺めてみると、次のように、関数real_toupper()のカバレッジ結果では、未実行の行は無いことがわかります。
-: 804:static gsize
-: 805:real_toupper (const gchar *str,
-: 806: gssize max_len,
-: 807: gchar *out_buffer,
-: 808: LocaleType locale_type)
function real_toupper called 6438 returned 100% blocks executed 87%
6438: 809:{
6438: 810: const gchar *p = str;
6438: 811: const char *last = NULL;
6438: 812: gsize len = 0;
6438: 813: gboolean last_was_i = FALSE;
-: 814:
19368: 815: while ((max_len < 0 || p < str + max_len) && *p)
-: 816: {
6492: 817: gunichar c = g_utf8_get_char (p);
6492: 818: int t = TYPE (c);
-: 819: gunichar val;
-: 820:
6492: 821: last = p;
6492: 822: p = g_utf8_next_char (p);
-: 823:
6492: 824: if (locale_type == LOCALE_LITHUANIAN)
-: 825: {
40: 826: if (c == 'i')
4: 827: last_was_i = TRUE;
-: 828: else
-: 829: {
36: 830: if (last_was_i)
-: 831: {
-: 832: /* Nasty, need to remove any dot above. Though
-: 833: * I think only E WITH DOT ABOVE occurs in practice
-: 834: * which could simplify this considerably.
-: 835: */
-: 836: gsize decomp_len, i;
-: 837: gunichar *decomp;
-: 838:
4: 839: decomp = g_unicode_canonical_decomposition (c, &decomp_len);
10: 840: for (i=0; i < decomp_len; i++)
-: 841: {
6: 842: if (decomp[i] != 0x307 /* COMBINING DOT ABOVE */)
4: 843: len += g_unichar_to_utf8 (g_unichar_toupper (decomp[i]), out_buffer ? out_buffer + len : NULL);
-: 844: }
4: 845: g_free (decomp);
-: 846:
4: 847: len += output_marks (&p, out_buffer ? out_buffer + len : NULL, TRUE);
-: 848:
4: 849: continue;
-: 850: }
-: 851:
32: 852: if (!ISMARK (t))
18: 853: last_was_i = FALSE;
-: 854: }
-: 855: }
-: 856:
6490: 857: if (locale_type == LOCALE_TURKIC && c == 'i')
-: 858: {
-: 859: /* i => LATIN CAPITAL LETTER I WITH DOT ABOVE */
2: 860: len += g_unichar_to_utf8 (0x130, out_buffer ? out_buffer + len : NULL);
-: 861: }
6486: 862: else if (c == 0x0345) /* COMBINING GREEK YPOGEGRAMMENI */
-: 863: {
-: 864: /* Nasty, need to move it after other combining marks .. this would go away if
-: 865: * we normalized first.
-: 866: */
4: 867: len += output_marks (&p, out_buffer ? out_buffer + len : NULL, FALSE);
-: 868:
-: 869: /* And output as GREEK CAPITAL LETTER IOTA */
4: 870: len += g_unichar_to_utf8 (0x399, out_buffer ? out_buffer + len : NULL);
-: 871: }
6482: 872: else if (IS (t,
-: 873: OR (G_UNICODE_LOWERCASE_LETTER,
-: 874: OR (G_UNICODE_TITLECASE_LETTER,
-: 875: 0))))
-: 876: {
3570: 877: val = ATTTABLE (c >> 8, c & 0xff);
-: 878:
3570: 879: if (val >= 0x1000000)
-: 880: {
206: 881: len += output_special_case (out_buffer ? out_buffer + len : NULL, val - 0x1000000, t,
-: 882: t == G_UNICODE_LOWERCASE_LETTER ? 0 : 1);
-: 883: }
-: 884: else
-: 885: {
3364: 886: if (t == G_UNICODE_TITLECASE_LETTER)
-: 887: {
-: 888: unsigned int i;
20: 889: for (i = 0; i < G_N_ELEMENTS (title_table); ++i)
-: 890: {
20: 891: if (title_table[i][0] == c)
-: 892: {
8: 893: val = title_table[i][1];
8: 894: break;
-: 895: }
-: 896: }
-: 897: }
-: 898:
-: 899: /* Some lowercase letters, e.g., U+000AA, FEMININE ORDINAL INDICATOR,
-: 900: * do not have an uppercase equivalent, in which case val will be
-: 901: * zero. */
3364: 902: len += g_unichar_to_utf8 (val ? val : c, out_buffer ? out_buffer + len : NULL);
-: 903: }
-: 904: }
-: 905: else
-: 906: {
2912: 907: gsize char_len = g_utf8_skip[*(guchar *)last];
-: 908:
2912: 909: if (out_buffer)
1456: 910: memcpy (out_buffer + len, last, char_len);
-: 911:
2912: 912: len += char_len;
-: 913: }
-: 914:
-: 915: }
-: 916:
6438: 917: return len;
-: 918:}
ところが実際には、命令カバレッジは100%ではありません。注目したいのは、次の行です。
function real_toupper called 6438 returned 100% blocks executed 87%これは基本ブロックのうち87%を実行したことを示しています。つまり、残り13%は実行されていないことになります。いったいどの部分を実行していないでしょうか。
まず、ソースコードを眺めると、三項演算子がいくつか使われているので、その条件式が常に真、または偽、になっているのでは、ということが思い付きます。しかし、そうだとしても、それで未実行の基本ブロックが13%にもなるのは不自然な気がします。
ソースコードを眺めるだけでは、これ以上のことは簡単にはわからないでしょう。そこで、covertureの出力結果とgraphvizを使って、次のような基本ブロックのフローグラフを作成してみました(クリックで拡大します)。

実行した基本ブロックは青で塗っています。また、実行した分岐も青い線で描画しています。ただし、図が煩雑になるので、FAKEのアークは波線で表しています。
図を眺めて、まず気になる点は、基本ブロック3から8へ向かうアークが未実行で、基本ブロック8から派生する一連のブロックが未実行になっていることです。該当する部分を拡大したものを次に示します。
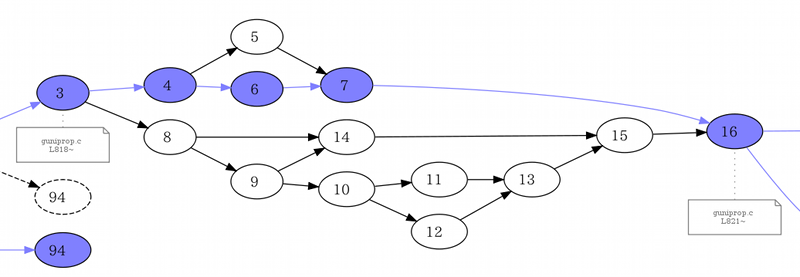
それらに対応するソースコードはどこになるのでしょうか。図から基本ブロック3が818行に、基本ブロック16が821行に対応していることがわかります。ソースコードの818行~821行は次のようになっています。
6492: 818: int t = TYPE (c);
-: 819: gunichar val;
-: 820:
6492: 821: last = p;
以上のことから、「基本ブロック3から16までの経路」はすべて818行に対応すると考えられます。これらのことから、TYPE()が怪しそうです。調べてみると、これは同じファイルで定義されている次のようなマクロでした。
-: 43:#define TTYPE_PART1(Page, Char) \
-: 44: ((type_table_part1[Page] >= G_UNICODE_MAX_TABLE_INDEX) \
-: 45: ? (type_table_part1[Page] - G_UNICODE_MAX_TABLE_INDEX) \
-: 46: : (type_data[type_table_part1[Page]][Char]))
-: 47:
-: 48:#define TTYPE_PART2(Page, Char) \
-: 49: ((type_table_part2[Page] >= G_UNICODE_MAX_TABLE_INDEX) \
-: 50: ? (type_table_part2[Page] - G_UNICODE_MAX_TABLE_INDEX) \
-: 51: : (type_data[type_table_part2[Page]][Char]))
-: 52:
-: 53:#define TYPE(Char) \
-: 54: (((Char) <= G_UNICODE_LAST_CHAR_PART1) \
-: 55: ? TTYPE_PART1 ((Char) >> 8, (Char) & 0xff) \
-: 56: : (((Char) >= 0xe0000 && (Char) <= G_UNICODE_LAST_CHAR) \
-: 57: ? TTYPE_PART2 (((Char) - 0xe0000) >> 8, (Char) & 0xff) \
-: 58: : G_UNICODE_UNASSIGNED))</pre>
TYPE()は三項演算子の盛り合わせのようなマクロであることがわかりました。そして、どうやらこのマクロを命令カバレッジするほどのテストは用意されていないようです。
† この関数に問題があるわけではありません。
実行したソースコード行数の割合とカバレッジ率
実行したソースコードの行数の割合をカバレッジ率として扱うことがよくあります。例えば、1000行のソースコードのうち、900行が実行されていれば、90%をカバレッジしたと考えてしまいがちです。
極端な例をあげてみましょう。次のような3つの基本ブロックに分岐する関数があり、そのうち1つだけが実行され、残りの2つは未実行であるとします。ただし、実行した基本ブロックの行数はソースコード中の98行に相当し、未実行のブロックの行数はそれぞれソースコード中の1行に相当するとします。
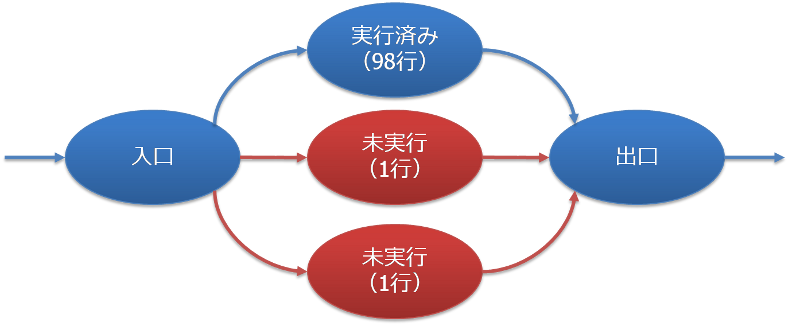
この関数はカバレッジ率98%のテストを実行したと言えるのでしょうか。それとも、1/3程度しかテストを実行していないのでしょうか。人によって意見は分かれるでしょうが、少なくても行数ベースでカバレッジ率を計算するだけでは、真の姿はわからないということです。
FreeBSD 8.0でカバレッジ
FreeBSD 8.0でgccにオプション-ftest-coverage -fprofile-arcs、もしくは-coverageを渡してビルドすると、次のようにundefined reference to `__stack_chk_fail_local'というエラーを表示して、リンクに失敗する場合があります。
% cat > test.c
int
main(void)
{
return 0;
}
^D
% gcc -coverage test.c
/usr/lib/libgcov.a(_gcov.o)(.text+0x145f): In function `gcov_exit':
: undefined reference to `__stack_chk_fail_local'
%
次のようにオプション-fstack-protectorを指定すると、ビルドできるようになります。
% gcc -coverage -fstack-protector test.c
%